Tiziano Cianti
Libero Professionista
Classe 1979, Appassionato da sempre per l'informatica inizio il percorso di studi nell'Istituto Tecnico Aldini-Valeriani e poi successivamente all'Università di Bologna in Scienze Informatiche. Le soluzioni che propongo ai clienti spaziano dalla creazione di un sito web/ e-commerce totalmente responsive, personalizzato secondo le esigenze del cliente, dalla gestione del dominio alla creazione di applicativi per ogni esigenza.

Realizzo siti Web, siti e-commerce, Applicazioni di Intelligenza Artificiale ( guarda la sezione portfolio ), e tutto quello che ne consegue (installazione, configurazione, monitoraggio del traffico in entrata, manutenzione, ottimizzazione, email marketing), Sviluppo di applicativi su specifica JEE, sviluppo di programmi multipiattaforma e anche su dispositivi mobile.

Ci proponiamo alle piccole/medie imprese di aiutarle ad avere visibilità su internet, risolvere problemi legati alla produzione, logistica... così da essere raggiunti da più utenti e quindi da potenziali clienti.

Promozione del sito attraverso tecniche di SEO e su altre piattaforme social.Realizzazione di applicazioni di Intelligenza Artificiale tramite le tecniche di Machine e Deep Learning.

Il cliente non viene mai lasciato solo a se stesso, vengono fornite le conoscenze di base nel gestire quel particolare sito/programma o problematica.





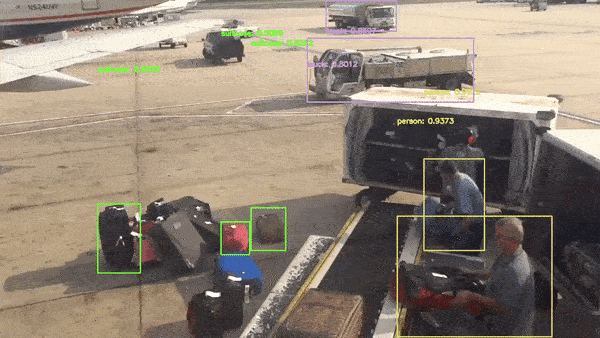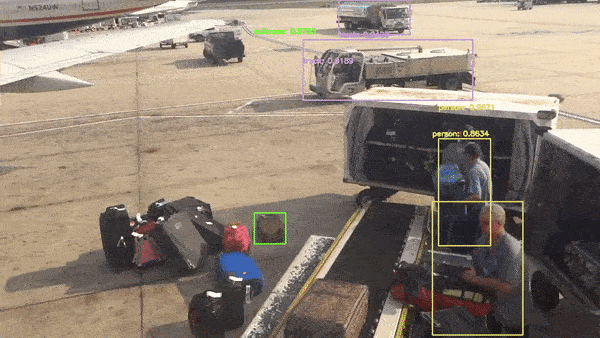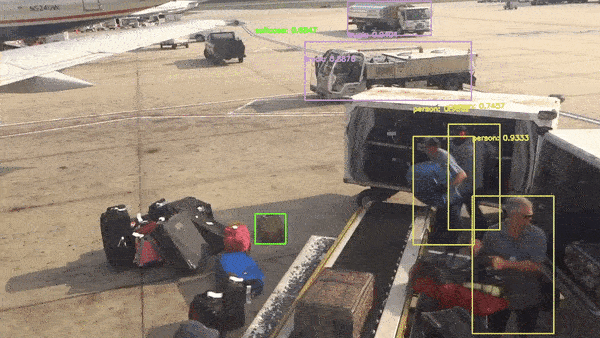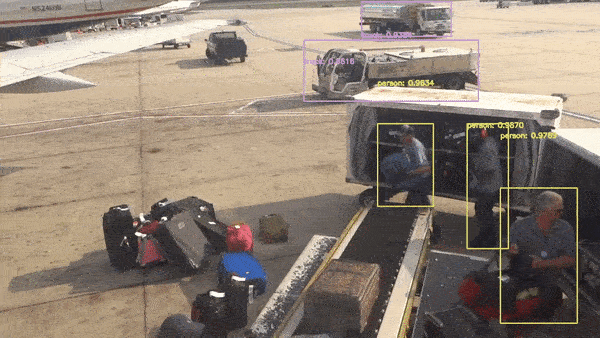



Blog
Intro AI
L'obiettivo centrale dell'intelligenza artificiale è quello di fornire una serie di algoritmi e tecniche
che possono essere utilizzate per risolvere i problemi che gli esseri umani eseguono in modo intuitivo e quasi automatico, ma sono comunque molto impegnativi per i computer. Un grande esempio di una tale classe di problemi di intelligenza artificiale è l'interpretazione e capire il contenuto di un'immagine: questo compito è qualcosa che un umano può fare con poco sforzo, ma estremamente difficile da realizzare per le macchine.
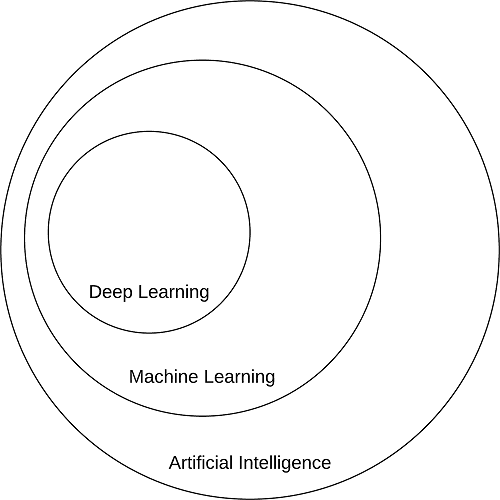
Mentre la AI incarna un insieme ampio e diversificato di lavori relativi al ragionamento automatico
della macchina (inferenza, pianificazione, euristica, ecc.), il sottocampo 'Machine Learning'
tende a essere specificamente interessato al riconoscimento di pattern e apprendimento
dai dati. Le reti neurali artificiali (ANNs) sono una classe di algoritmi di apprendimento automatico
da cui apprendere dati e specializzati nel riconoscimento di modelli, ispirati alla struttura e alla
funzione del cervello. L'apprendimento approfondito appartiene alla famiglia
degli algoritmi di ANN e, nella maggior parte dei casi, i due i termini possono essere usati in modo intercambiabile.
 La storia delle reti neurali e dell'apprendimento profondo è lunga e un po 'confusa. Può
sorprendere sapere che "l'apprendimento profondo" esiste dagli anni '40 sotto vari nomi.
Mentre sono ispirati dal cervello umano e come i suoi neuroni interagiscono tra loro, le
ANNs non sono intesi per essere modelli realistici del cervello. Invece, sono un'ispirazione, che
ci permette di disegnare paralleli tra un modello molto basilare del cervello e come possiamo
imitare alcuni di questi comportamenti attraverso reti neurali artificiali.
Oggi, l'ultima incarnazione delle reti neurali come la conosciamo è chiamata deep learning. Ora che abbiamo hardware più veloce e specializzato con più dati di allenamento disponibili possiamo
addestrare reti con molti livelli nascosti, capaci di apprendimento gerarchico in cui
vengono appresi concetti semplici negli strati inferiori, e altri modelli astratti negli strati superiori della rete. Forse l'esempio per eccellenza dell'apprendimento profondo applicato all'apprendimento funzionale è il Convolutional Neural Network (LeCun 1988) si applicava al riconoscimento di caratteri manoscritti che impara automaticamente i pattern discriminanti (chiamati "filtri") dalle immagini impilando sequenzialmente strati uno sopra l'altro. I filtri nei livelli inferiori della rete rappresentano i bordi e gli angoli, mentre i livelli più alti usano i bordi e gli angoli per imparare più concetti astratti utili per discriminare tra classi di immagini.
In molte applicazioni, le CNN sono ora considerate il più potente classificatore di immagini e lo
sono attualmente responsabile di far avanzare lo stato dell'arte nei sottocampi di visione artificiale
che fanno leva apprendimento automatico.
La storia delle reti neurali e dell'apprendimento profondo è lunga e un po 'confusa. Può
sorprendere sapere che "l'apprendimento profondo" esiste dagli anni '40 sotto vari nomi.
Mentre sono ispirati dal cervello umano e come i suoi neuroni interagiscono tra loro, le
ANNs non sono intesi per essere modelli realistici del cervello. Invece, sono un'ispirazione, che
ci permette di disegnare paralleli tra un modello molto basilare del cervello e come possiamo
imitare alcuni di questi comportamenti attraverso reti neurali artificiali.
Oggi, l'ultima incarnazione delle reti neurali come la conosciamo è chiamata deep learning. Ora che abbiamo hardware più veloce e specializzato con più dati di allenamento disponibili possiamo
addestrare reti con molti livelli nascosti, capaci di apprendimento gerarchico in cui
vengono appresi concetti semplici negli strati inferiori, e altri modelli astratti negli strati superiori della rete. Forse l'esempio per eccellenza dell'apprendimento profondo applicato all'apprendimento funzionale è il Convolutional Neural Network (LeCun 1988) si applicava al riconoscimento di caratteri manoscritti che impara automaticamente i pattern discriminanti (chiamati "filtri") dalle immagini impilando sequenzialmente strati uno sopra l'altro. I filtri nei livelli inferiori della rete rappresentano i bordi e gli angoli, mentre i livelli più alti usano i bordi e gli angoli per imparare più concetti astratti utili per discriminare tra classi di immagini.
In molte applicazioni, le CNN sono ora considerate il più potente classificatore di immagini e lo
sono attualmente responsabile di far avanzare lo stato dell'arte nei sottocampi di visione artificiale
che fanno leva apprendimento automatico.
Classificazione delle Immagini
La classificazione delle immagini, nella sua essenza, è il compito di assegnare un'etichetta a un'immagine da una predefinita insieme di categorie. Dato che tutto ciò che un computer vede è una grande matrice di pixel, arriviamo al problema del divario semantico. Il divario semantico è la differenza tra il modo in cui un essere umano percepisce il contenuto di un'immagine rispetto a come un'immagine può essere rappresentata in un modo in cui un computer può comprendere il processo. Se il divario semantico non fosse abbastanza di un problema, dobbiamo anche gestire i fattori di variazione nel modo in cui appare un'immagine o un oggetto. Per iniziare, abbiamo una variazione del punto di vista, in cui un oggetto può essere orientato / ruotato in più dimensioni rispetto a come l'oggetto è fotografato e catturato. Non importa l'angolo in che catturiamo questo oggetto, è sempre lo stesso oggetto. Dobbiamo anche tenere conto delle variazioni di scala un bicchiere sia piccolo che grande è sempre un bicchiere per esempio.I nostri metodi di classificazione delle immagini devono essere tollerabili a questi tipi di variazioni di scala.La nostra classificazione delle immagini dovrebbe anche essere in grado di gestire le occlusioni, dove grandi parti del soggetto sono nascoste. Gli algoritmi di classificazione delle immagini dovrebbero ancora essere in grado di rilevare ed etichettare.Altrettanto difficili come le deformazioni e le occlusioni sopra menzionate, dobbiamo anche gestire i cambiamenti nell'illuminazione.Non è sufficiente che il nostro sistema di classificazione delle immagini sia solido a queste variazioni in modo indipendente, ma il nostro sistema deve anche gestire più variazioni combinate insieme! Tenete presente che ImageNet, il set di dati benchmark standard di fatto per la classificazione delle immagini algoritmi, consiste di 1.000 oggetti che incontriamo nella nostra vita quotidiana - e questo insieme di dati è ancora attivamente utilizzato dai ricercatori che cercano di portare avanti lo stato dell'arte per un apprendimento approfondito.Pertanto, invece di provare a costruire un sistema basato su regole per descrivere ciò che ciascuna categoria "sembra", possiamo invece adottare un approccio basato sui dati fornendo esempi di cosa ogni categoria sembra e quindi insegnare il nostro algoritmo per riconoscere la differenza. Chiamiamo questi esempi il nostro set di dati di formazione di immagini etichettate, in cui ogni punto di dati nel nostro il set di dati di addestramento consiste di: 1. Un'immagine 2. L'etichetta / categoria (cioè auto, cavallo, libro ecc.) dell'immagine Ancora una volta, è importante che ognuna di queste immagini abbia etichette associate a loro perché il nostro l'algoritmo di apprendimento supervisionato dovrà vedere queste etichette per "insegnare a se stesso" come riconoscere le categorie. Tenendo presente questo, andiamo avanti e lavoriamo attraverso i quattro passaggi per costruire un modello di apprendimento profondo. Passo 1: Raccogliere il set di dati Il primo componente della costruzione di una rete di deep learning è la raccolta del nostro set di dati iniziale. Abbiamo bisogno delle immagini stesse e le etichette associate a ciascuna immagine. Queste etichette dovrebbero venire da un insieme finito di categorie, quali: categorie = auto, cavallo, libro. Inoltre, il numero di immagini per ogni categoria dovrebbe essere approssimativamente uniforme (ad es. lo stesso numero di esempi per categoria). Lo squilibrio di classe è un problema quindi è meglio evitarlo. Passaggio 2: dividere il set di dati Ora che abbiamo il nostro set di dati iniziale, dobbiamo dividerlo in due parti: 1. Un set di allenamento 2. Un set di test Il nostro classificatore utilizza un set di allenamento per "apprendere" l'aspetto di ogni categoria previsioni sui dati di input e quindi correggersi quando le previsioni sono sbagliate. Dopo il classificatore è stato addestrato, possiamo valutare l'esecuzione su un set di test. È estremamente importante che il set di allenamento e il set di test siano indipendenti l'uno dall'altro e non sovrapporre! Se si utilizza il set di test come parte dei dati di allenamento, quindi il classificatore ha un vantaggio ingiusto poiché ha già visto gli esempi di test prima e "imparato" da loro. Invece, è necessario mantenere questo set di test completamente separato dal processo di allenamento e utilizzarlo solo per valutare la tua rete. Passo 3: Allena la tua rete Dato il nostro set di immagini di formazione, ora possiamo addestrare la nostra rete. L'obiettivo qui è per la nostra rete impara come riconoscere ciascuna delle categorie nei nostri dati etichettati. Quando il modello commette un errore, impara da questo errore e migliora se stesso. Passo 4: valutare Infine, dobbiamo valutare la nostra rete formata. Per ognuna delle immagini nel nostro set di test, presentiamo li alla rete e chiedono di prevedere cosa pensa che sia l'etichetta dell'immagine. Quindi tabuliamo le previsioni del modello per un'immagine nel set di test.Infine, queste previsioni del modello vengono confrontate con le etichette di verità di base del nostro set di test. Le etichette di verità di base rappresentano ciò che la categoria di immagini è in realtà. Da lì, possiamo calcolare il numero di previsioni che il nostro classificatore ha calcolato, per quantificare le prestazioni della nostra rete nel suo complesso.
Machine Learning
Un sistema di Machine Learning (apprendimento automatico) durante la fase di training apprende a
partire da esempi (in modo più o meno supervisionato). Successivamente è in grado di generalizzare
e gestire nuovi dati nello stesso dominio applicativo.
Machine Learning è oggi ritenuto uno dei approcci più importanti dell’intelligenza artificiale.
I dati sono un ingrediente fondamentale del machine learning, dove il comportamento degli
algoritmi non è pre-programmato ma appreso dai dati stessi.
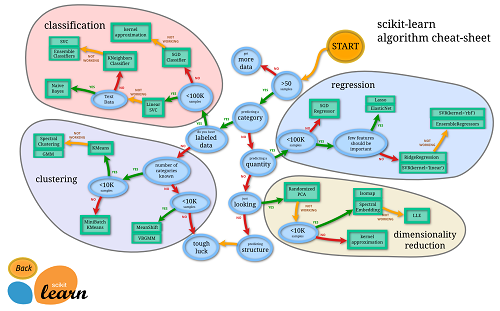
Nel corso del tempo, sono stati sviluppati molti approcci di apprendimento automatico delle
macchine. Puoi usare questa mappa dal team di scikit-learn come guida per i metodi più popolari.
 Classificazione: assegna una classe a un pattern.
Il concetto di classe è semantico e dipende strettamente dall’applicazione: per esempio 10 classi per
il riconoscimento delle cifre da 0-9.
Esempi di problemi di classificazione:
• Emotion recognition
• Face recognition
• Pedestrian classification
Regressione: assegna un valore continuo a un pattern.
Utile per la predizione di valori continui.
Esempi di problemi di regressione:
• Object detection
• Stima prezzi vendita appartamenti nel mercato immobiliare
• Stima del rischio per compagnie assicurative
Clustering: individua gruppi (cluster) di pattern con caratteristiche simili.
Le classi del problema non sono note e i pattern non etichettati rendendo così la natura non
supervisionata del problema più complesso della classificazione.
I cluster individuati nell’apprendimento possono essere poi utilizzati come classi.
Esempi di problemi di clustering:
• Marketing segmentation
• Social network analysis
• Search result grouping
• Medical imaging
• Image segmentation
Riduzione di dimensionalità: riduce il numero di dimensioni dei pattern in input.
Il successo di molte applicazioni di machine learning dipende dall’efficacia di rappresentazione dei
pattern in termini di estrazioni delle caratteristiche.
Ad esempio per il riconoscimento di oggetti esistono numerosi descrittori di forma, colore e texture
che possiamo utilizzare per convertire immagini in vettori numerici.
Data un'immagine di input di pixel, applicheremmo il nostro algoritmo per i pixel, e in cambio
riceviamo un vettore di funzionalità che quantifica il contenuto dell'immagine. I vettori di
caratteristiche che risultavano dall'estrazione delle caratteristiche sono ciò che noi siamo veramente
interessati in quanto servono da input per i nostri modelli di apprendimento automatico.
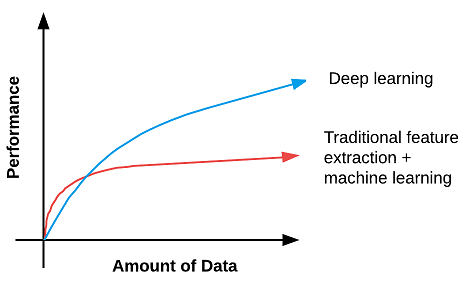
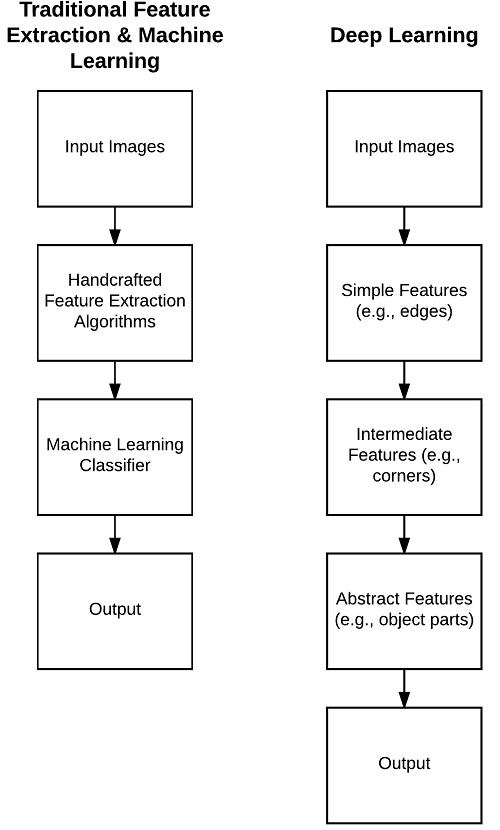
Nella figura di seguito a sinistra: il processo tradizionale di prendere una serie di immagini in input,
applicare una serie di algoritmi di estrazione delle caratteristiche, seguito dalla formazione di un
classificatore di apprendimento automatico sulle funzionalità.
A destra: l'approccio di apprendimento approfondito per sovrapporre strati sovrapposti che
apprendono automaticamente le funzioni più complesse, astratte e discriminanti.
Classificazione: assegna una classe a un pattern.
Il concetto di classe è semantico e dipende strettamente dall’applicazione: per esempio 10 classi per
il riconoscimento delle cifre da 0-9.
Esempi di problemi di classificazione:
• Emotion recognition
• Face recognition
• Pedestrian classification
Regressione: assegna un valore continuo a un pattern.
Utile per la predizione di valori continui.
Esempi di problemi di regressione:
• Object detection
• Stima prezzi vendita appartamenti nel mercato immobiliare
• Stima del rischio per compagnie assicurative
Clustering: individua gruppi (cluster) di pattern con caratteristiche simili.
Le classi del problema non sono note e i pattern non etichettati rendendo così la natura non
supervisionata del problema più complesso della classificazione.
I cluster individuati nell’apprendimento possono essere poi utilizzati come classi.
Esempi di problemi di clustering:
• Marketing segmentation
• Social network analysis
• Search result grouping
• Medical imaging
• Image segmentation
Riduzione di dimensionalità: riduce il numero di dimensioni dei pattern in input.
Il successo di molte applicazioni di machine learning dipende dall’efficacia di rappresentazione dei
pattern in termini di estrazioni delle caratteristiche.
Ad esempio per il riconoscimento di oggetti esistono numerosi descrittori di forma, colore e texture
che possiamo utilizzare per convertire immagini in vettori numerici.
Data un'immagine di input di pixel, applicheremmo il nostro algoritmo per i pixel, e in cambio
riceviamo un vettore di funzionalità che quantifica il contenuto dell'immagine. I vettori di
caratteristiche che risultavano dall'estrazione delle caratteristiche sono ciò che noi siamo veramente
interessati in quanto servono da input per i nostri modelli di apprendimento automatico.
Nella figura di seguito a sinistra: il processo tradizionale di prendere una serie di immagini in input,
applicare una serie di algoritmi di estrazione delle caratteristiche, seguito dalla formazione di un
classificatore di apprendimento automatico sulle funzionalità.
A destra: l'approccio di apprendimento approfondito per sovrapporre strati sovrapposti che
apprendono automaticamente le funzioni più complesse, astratte e discriminanti.
 Ma si possono apprendere automaticamente le caratterische efficaci delle immagini a partire da raw
data? O analogamente, possiamo operare direttamente sulle caratteristiche (es. intensità dei pixel di
un’immagine, ampiezza di un segnale audio nel tempo) senza utilizzare feature pre-definite ?
Gran parte delle tecniche di deep learning (es. convolutional neural networks) operano in questo
modo, utilizzando come input i raw data ed estraendo automaticamente da essi le feature necessarie
per risolvere il problema di interesse. Invece di definire manualmente una serie di regole e algoritmi
per estrarre le caratteristiche da un'immagine, queste le caratteristiche vengono invece apprese
automaticamente dal processo di formazione. Data un'immagine, forniamo i valori di intensità del
pixel come input alla rete. Una serie di nascosti i livelli sono usati per estrarre le caratteristiche dalla
nostra immagine di input. Questi strati nascosti si fondono l'un l'altro in modo gerarchico.
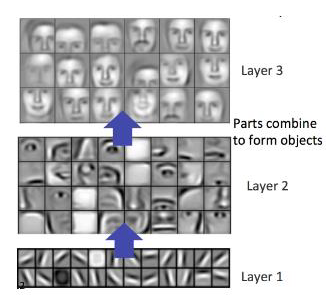
Inizialmente, solo le regioni di tipo edge vengono rilevate negli strati di livello inferiore di il
network. Queste aree del bordo vengono utilizzate per definire gli angoli (dove i bordi si
intersecano) e i contorni (contorni di oggetti). La combinazione di angoli e contorni può portare a
"parti dell'oggetto" astratte nel prossimo strato. Possiamo osservare questo processo come
apprendimento gerarchico: ogni strato della rete utilizza l'output di strati precedenti come "elementi
costitutivi" per costruire concetti sempre più astratti. Questi livelli vengono appresi
automaticamente - non sono stati usati algoritmi di estrazione delle caratteristiche nella Rete.
Ma si possono apprendere automaticamente le caratterische efficaci delle immagini a partire da raw
data? O analogamente, possiamo operare direttamente sulle caratteristiche (es. intensità dei pixel di
un’immagine, ampiezza di un segnale audio nel tempo) senza utilizzare feature pre-definite ?
Gran parte delle tecniche di deep learning (es. convolutional neural networks) operano in questo
modo, utilizzando come input i raw data ed estraendo automaticamente da essi le feature necessarie
per risolvere il problema di interesse. Invece di definire manualmente una serie di regole e algoritmi
per estrarre le caratteristiche da un'immagine, queste le caratteristiche vengono invece apprese
automaticamente dal processo di formazione. Data un'immagine, forniamo i valori di intensità del
pixel come input alla rete. Una serie di nascosti i livelli sono usati per estrarre le caratteristiche dalla
nostra immagine di input. Questi strati nascosti si fondono l'un l'altro in modo gerarchico.
Inizialmente, solo le regioni di tipo edge vengono rilevate negli strati di livello inferiore di il
network. Queste aree del bordo vengono utilizzate per definire gli angoli (dove i bordi si
intersecano) e i contorni (contorni di oggetti). La combinazione di angoli e contorni può portare a
"parti dell'oggetto" astratte nel prossimo strato. Possiamo osservare questo processo come
apprendimento gerarchico: ogni strato della rete utilizza l'output di strati precedenti come "elementi
costitutivi" per costruire concetti sempre più astratti. Questi livelli vengono appresi
automaticamente - non sono stati usati algoritmi di estrazione delle caratteristiche nella Rete.
 Nei prossimi articoli parleremo più dettagliatamente delle tecniche di deep learning applicate alla computer vision.
Nei prossimi articoli parleremo più dettagliatamente delle tecniche di deep learning applicate alla computer vision.
Reti Neurali
Le reti neurali sono gli elementi costitutivi dei sistemi di deep learning.
Cosa sono le reti neurali?
Molte attività che implicano l'intelligenza, il riconoscimento di pattern e il rilevamento di oggetti
sono estremamente difficili da automatizzare, ma sembrano essere eseguite facilmente e
naturalmente da animali e bambini. Per esempio, in che modo il cane di famiglia riconosce, il
proprietario, rispetto a uno sconosciuto?
Come fa un bambino piccolo a imparare a riconoscere la differenza tra uno scuolabus e un normale
autobus ?
E in che modo i nostri cervelli eseguono inconsciamente compiti di riconoscimento di schemi
complessi ogni giorno senza che nessuno se ne accorga?
La risposta sta nel nostro corpo. Ognuno di noi contiene una neurale biologica reale
reti che sono collegate al nostro sistema nervoso - questa rete è composta da un gran numero di
neuroni interconnessi (cellule nervose). La parola "neurale" è la forma aggettivale di "neurone" e
"rete" indica un grafico struttura; quindi, una "Rete Neurale Artificiale" è un sistema di calcolo che
tenta di imitare (o almeno, è ispirato da) le connessioni neurali nel nostro sistema nervoso. Reti
neurali artificiali sono indicati anche come "reti neurali" o "sistemi neurali artificiali". È comune
abbreviare Rete neurale artificiale e fare riferimento ad essi come "ANN" o semplicemente "NN".
Affinché un sistema sia considerato un NN, deve contenere una struttura del grafo orientata e
etichettata dove ciascun nodo nel grafico esegue alcuni semplici calcoli. Dalla teoria dei grafi,
sappiamo che a il grafico diretto consiste di un insieme di nodi (cioè, i vertici) e un insieme di
connessioni (cioè i bordi) che collegano insieme coppie di nodi.
Nella Figura sottostante possiamo vedere un esempio di tale grafico NN.
Gli input sono presentati alla rete. Ogni connessione trasporta un segnale attraverso il livello
nascosto nella rete. Una funzione finale calcola le etichette delle classi di output.
 Relazione con la biologia
Relazione con la biologia
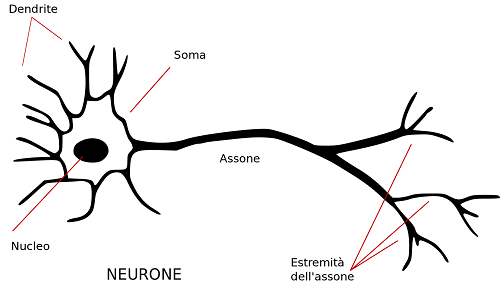 I neuroni sono collegati ad altri neuroni attraverso i loro dendriti e neuroni.
Il nostro cervello è composto da circa 10 miliardi di neuroni, ciascuno collegato a circa 10.000
altri neuroni. Il corpo cellulare del neurone è chiamato soma, dove gli input (dendriti) e
le uscite (assoni) collegano il soma ad altri soma.
Ogni neurone riceve input elettrochimici da altri neuroni ai loro dendriti. Se questi
gli input elettrici sono sufficientemente potenti per attivare il neurone, quindi il neurone attivato
trasmette il segnale lungo il suo assone, passando lungo i dendriti di altri neuroni.
La chiave del “funzionamento” è che un neurone può essere acceso o spento un'operazione binaria
non ci sono diversi "gradi" di attivazione. In poche parole, un neurone sparerà solo
se il segnale totale ricevuto al soma supera una determinata soglia.
L'obiettivo dell'apprendimento profondo non è quello di imitare come funziona il nostro cervello,
ma piuttosto prendere i pezzi che capiamo e che ci permettono di tracciare parallelismi simili nel
nostro lavoro.
Neurone Artificiale
Primo modello del 1943 di McCulloc hand Pitts. Con input e output binari era in grado di eseguire
computazioni logiche.
I neuroni sono collegati ad altri neuroni attraverso i loro dendriti e neuroni.
Il nostro cervello è composto da circa 10 miliardi di neuroni, ciascuno collegato a circa 10.000
altri neuroni. Il corpo cellulare del neurone è chiamato soma, dove gli input (dendriti) e
le uscite (assoni) collegano il soma ad altri soma.
Ogni neurone riceve input elettrochimici da altri neuroni ai loro dendriti. Se questi
gli input elettrici sono sufficientemente potenti per attivare il neurone, quindi il neurone attivato
trasmette il segnale lungo il suo assone, passando lungo i dendriti di altri neuroni.
La chiave del “funzionamento” è che un neurone può essere acceso o spento un'operazione binaria
non ci sono diversi "gradi" di attivazione. In poche parole, un neurone sparerà solo
se il segnale totale ricevuto al soma supera una determinata soglia.
L'obiettivo dell'apprendimento profondo non è quello di imitare come funziona il nostro cervello,
ma piuttosto prendere i pezzi che capiamo e che ci permettono di tracciare parallelismi simili nel
nostro lavoro.
Neurone Artificiale
Primo modello del 1943 di McCulloc hand Pitts. Con input e output binari era in grado di eseguire
computazioni logiche.
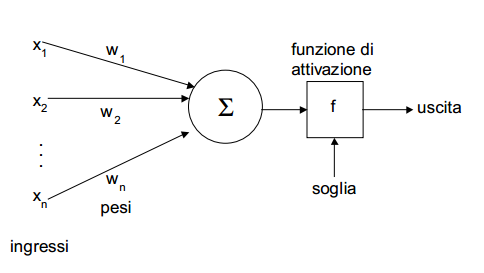 Modello Artificiale
La figura mostra una NN semplice che prende la somma ponderata dell'input x e dei pesi w. Questa
somma viene quindi passata attraverso la funzione di attivazione per determinare se il neurone
spara.
Modello Artificiale
La figura mostra una NN semplice che prende la somma ponderata dell'input x e dei pesi w. Questa
somma viene quindi passata attraverso la funzione di attivazione per determinare se il neurone
spara.
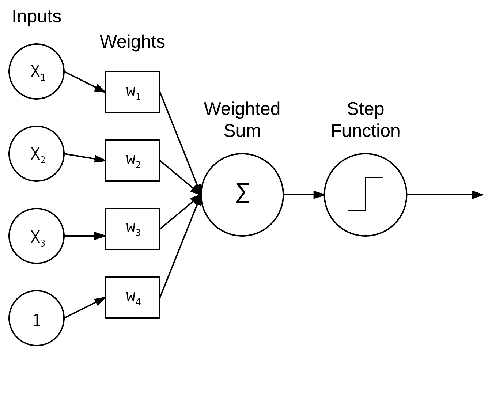 I valori x1; x2; e; x3 sono gli input per la nostra NN.Il valore costante 1 è il nostro pregiudizio detto
bias che si considera collegato ad un input fittizio con valore sempre a 1; questo peso è utile per
“tarare” il punto di lavoro ottimale del neurone.
In pratica questi input potrebbero essere vettori usati per quantificare il contenuto di un'immagine in
modo sistematico, modo predefinito (e.x., istogrammi colore, istogramma di gradienti orientati,
ecc.). Nel contesto dell'apprendimento profondo, questi input sono l'intensità dei pixel grezzi delle
immagini stesse.
Ogni x è connessa a un neurone tramite un peso vector W consiste di w1; w2; ::: wn, cioè quello
per ogni ingresso x abbiamo anche un peso associato w.
Infine, il nodo di output sulla destra della figura prende la somma ponderata, applica un'attivazione
funzione f (usata per determinare se il neurone "spara" o meno) e emette un valore.
I valori x1; x2; e; x3 sono gli input per la nostra NN.Il valore costante 1 è il nostro pregiudizio detto
bias che si considera collegato ad un input fittizio con valore sempre a 1; questo peso è utile per
“tarare” il punto di lavoro ottimale del neurone.
In pratica questi input potrebbero essere vettori usati per quantificare il contenuto di un'immagine in
modo sistematico, modo predefinito (e.x., istogrammi colore, istogramma di gradienti orientati,
ecc.). Nel contesto dell'apprendimento profondo, questi input sono l'intensità dei pixel grezzi delle
immagini stesse.
Ogni x è connessa a un neurone tramite un peso vector W consiste di w1; w2; ::: wn, cioè quello
per ogni ingresso x abbiamo anche un peso associato w.
Infine, il nodo di output sulla destra della figura prende la somma ponderata, applica un'attivazione
funzione f (usata per determinare se il neurone "spara" o meno) e emette un valore.
Contact Us


write us
info@tcai.it